Human Pose Estimation Using Deep Learning
This was my first ever deep learning project and so I am happy to share what I did there with some key insights. This is from 2014/15, when tensorflow didn’t even exist. Theano did, though.
Introduction
On a high level, human pose estimation from images of humans posing is the task of extracting features from the 2D images and then learn a mapping from the feature space to the 3D pose space. This post discusses how we use a deep convolutional neural network pre-trained on a related task as our machine learning model to obtain better than state-of-the-art results.
A word on dataset
Human36M is a well known human pose dataset that we have used in this work. It provides 3.6 milion video frames with labeled poses of 11 human subjects, performing 17 tasks/scenarios, recorded from 4 camera angles. This huge size of data makes it possible for deep networks to train effectively. In our present work, we restrict to using only ‘Walking’ action out of the 17 available for both training and testing.
The raw data from the dataset requires fair amount of pre-processing for both the images as well as the corresponding poses. The images are available as video frames, hence we need to perform operations like
- cropping,
- background subtraction,
- image compression and
- RGB to grayscale conversion,
before actually feeding them as inputs to the deep networks. Here is a sample image before and after our preprocessing steps:


Similarly, the pose data is processed equivalently to match the modified images. For each image, its equivalent pose is basically the 32 body joints, out of which we use only 17 main joints, leaving aside unimportant joints like fingers, toes, etc. Hence out target pose vectors are 51-sized vectors (17 x 3, 1 number for each of x, y and z- axis). Here is how the 17 body-joints look like for the same image shown above:

Overall, we use approximately 0.15 million images as input for training and 0.01 million images for testing our results.
Pre-training on a related task
We first trained a deep CNN on this pose regression task with the images as input and pose points as output. There were two major shortcomings:
- took far too long to learn, random weights perhaps were a harsh start.
- performance on test set was way worse than the benchmark at the time.
The inference here was that the regression task was perhaps too hard to perform, especially directly from scratch. This shouldn’t be a surprise as regression tasks are proven to be more difficult than classification tasks in context of neural networks, as also touched upon in this excellent course:
When faced with a regression task, first consider if it is absolutely necessary. Instead, have a strong preference to discretizing your outputs to bins and perform classification over them whenever possible.
To make the task more feasible to be learnt, inspired by this paper, we defined a related classification task to pre-train the model, so that the model weights are better suited to then learn the regression task. For each input image, we overlaid a 10X10 on top of it. And then we ask the classifier, for each of the 17 joints, which grids out of the 100, does the joint overlap with. The overlap here has a definition which will become apparent from the images below:
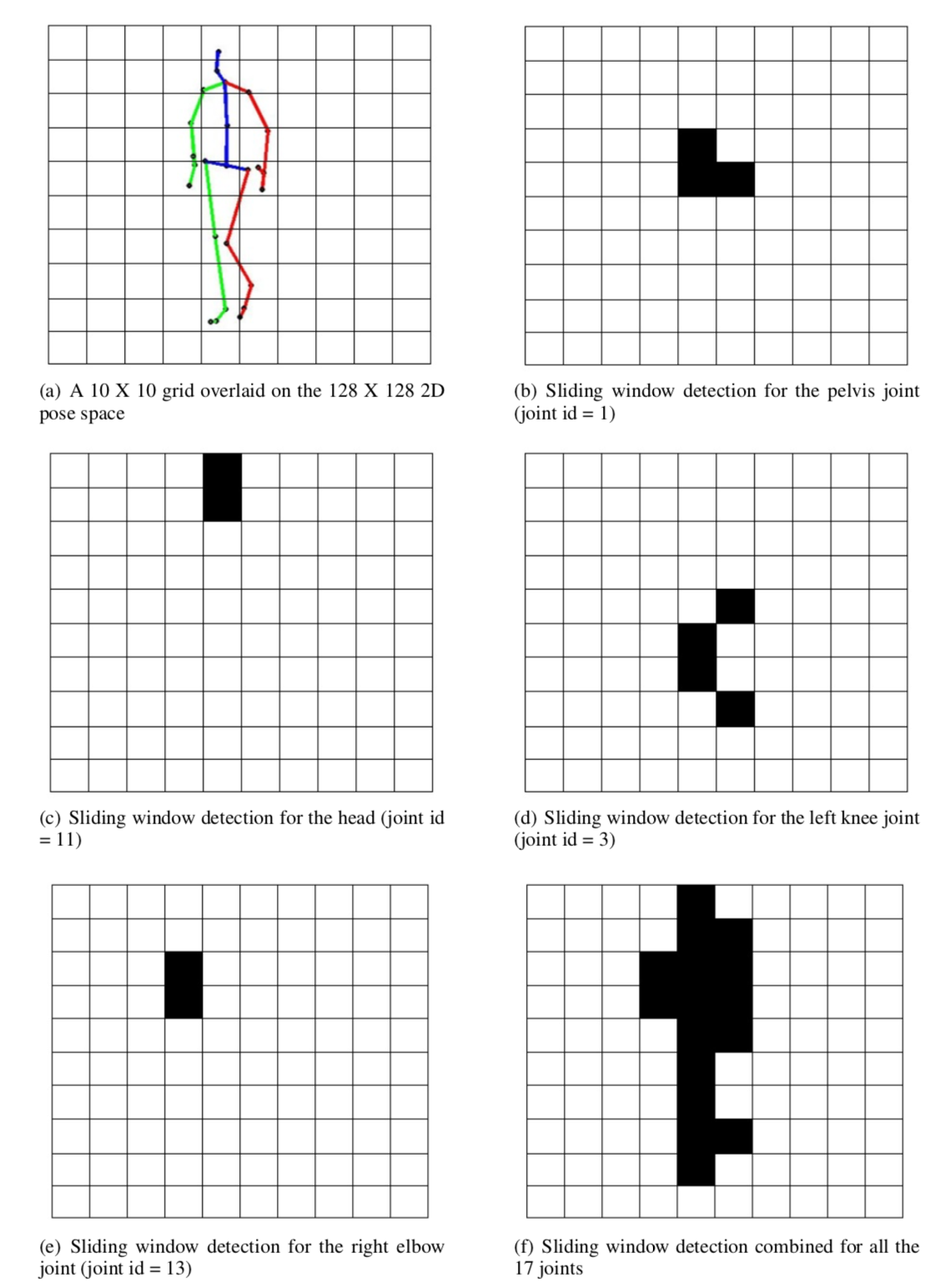
The target for this classification task is then, basically, a 1700 X 1 vector.
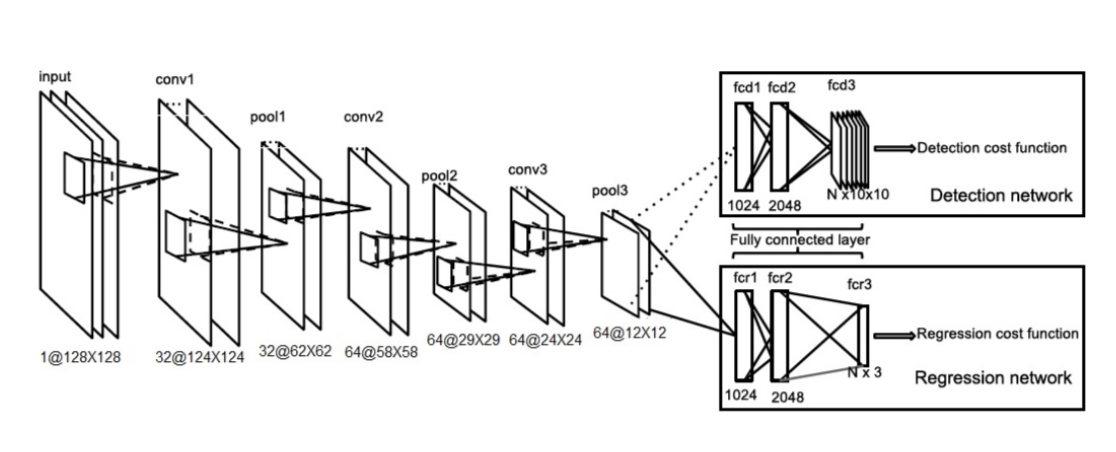
Model architecture and training
We first train the classification model on cross-entropy loss function, save the weights of the model, replace the last classification layer with the regression layer, reload weights, and train the regression model on mean per joint position error (details can be read here ). Here is the overall network architecture that was employed:
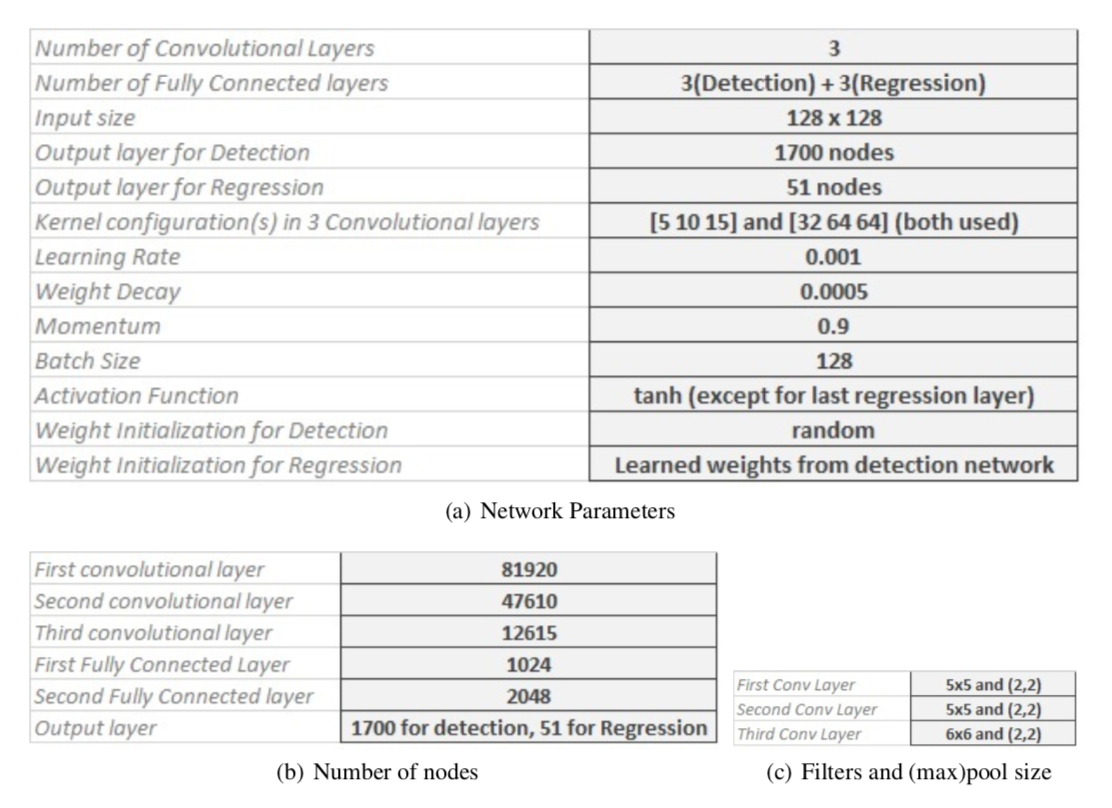
Not only is this task learnt faster by the model, the pre-trained weights dramatically speed-up the regression learning task, and resulting in better than state-of-the-art test set performance. Below are the learning curve snapshots for both the classification and regression tasks:
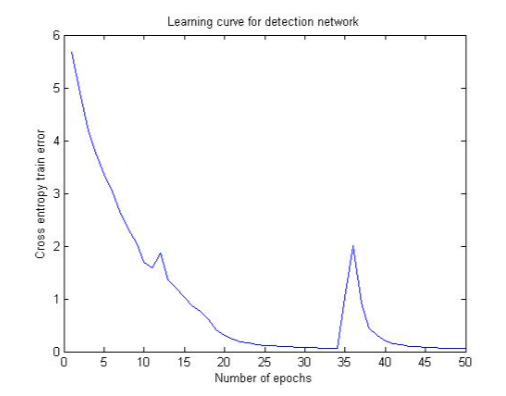
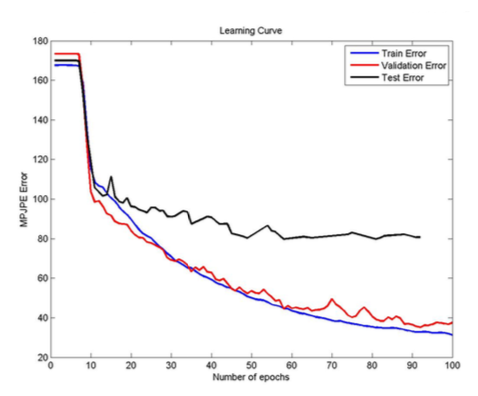
Fine details of model and dataset can be found in the original article
And, the model training script, here.
Sample Results
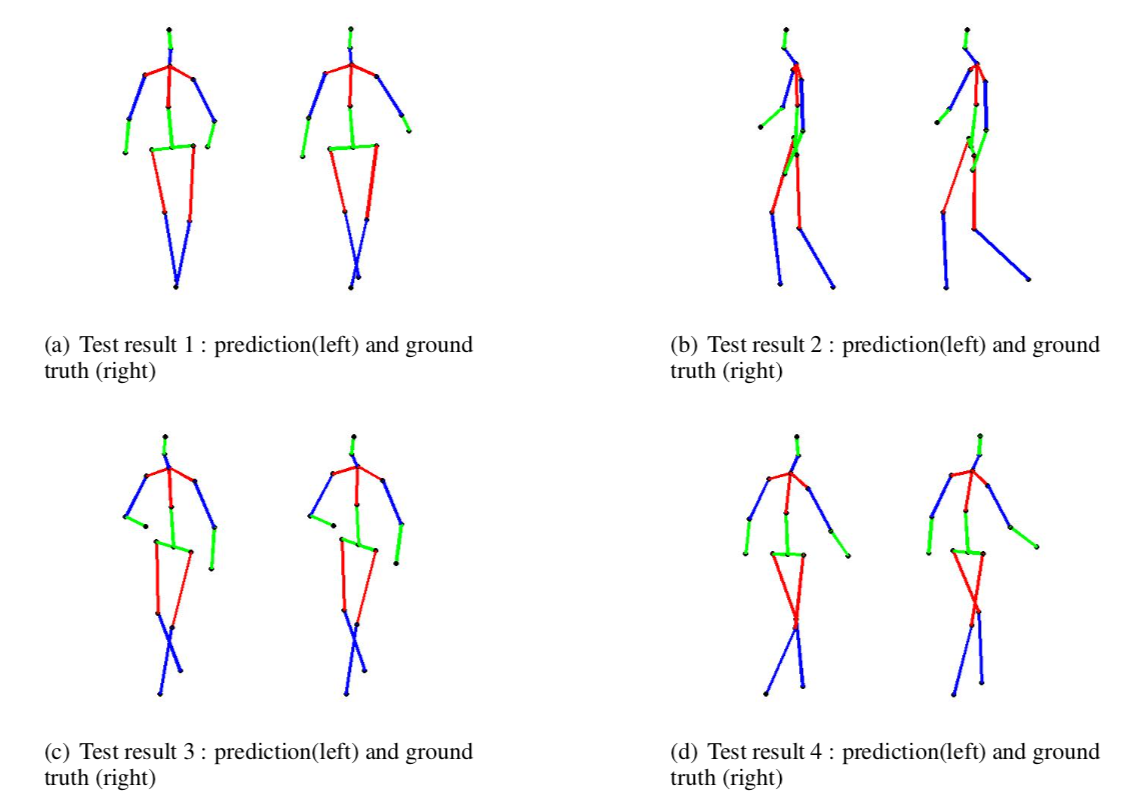
To give an idea of how the model performed in estimating the pose points for a given test image, below are 4 randomly chosen test samples, with their actual and estimate pose joints:
Additionally, to come back to the original data format which was videos basically, we reconstructed how real-time pose estimation for a walking person would look like. Here goes: (recommended to watch @ 2x)
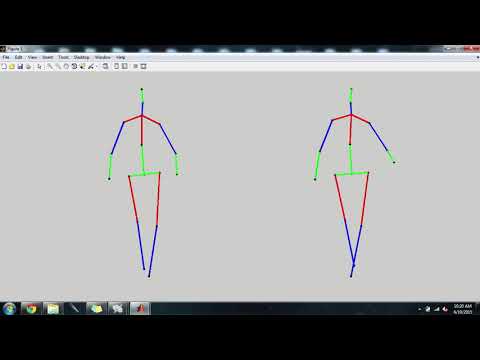
Validation Set Results
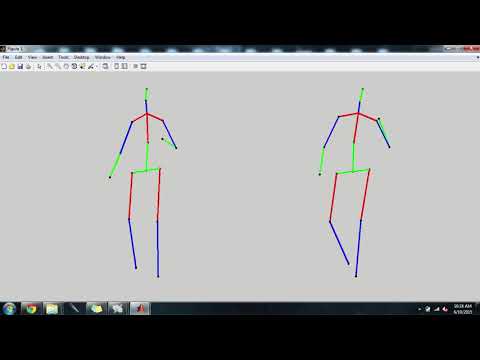
Test Set Results
Acknowledgements
Heartfelt thanks to EPFL, Prof. Pascal Fua for the opportunity to work on this project. Big thank you to Bugra Tekin for the amazing supervision, as well as Arun Ramakrishnan for collaborating on this one !