Youtube Comments Machine Learning
Youtube is the biggest and most popular steaming platform at the time of writing this post. For every youtube video, viewers post comments. I am a personal fan of reading many of those funny ones. In general, these comments also give away the popular topics of discussion, and a sentiment around the video.
Introduction
In this blog post, I share my work in utilising these comments to provide the most popular topics that are being talked about in the comments, and a general sentiment based on the language of these comments. A by-product of this project is a chrome extension, that I haven’t published yet, but one can locally clone the repo an use the extension locally.
Data Access
We use the youtube data api to pull the list of comments for a given youtube video id. Note: this has a quota limit per day. As the api response we get a list of strings in return for the video id as the api request parameter.
Word count
One of the indicators of topics being discussed in the comments is the most frequent words (except the stop-words). We follow a 2-step process here:
- Lemmatize the text.
- Compute word frequencies across comments after lemmatization.
Topic Modelling
Latent Semantic Analysis is one of the most popular and effective classical topic modelling technique in literature. Here are the steps we take to fetch topics out of the youtube comments:
1 . Tokenize the text i.e. lemmatize -> get rid of stop words / punctuations / pronouns, etc.
(Note : our current approach is limited to doing so for assuming the comments are in English)

2 . We need to move from words to numbers, hence we replace words with their count vectors i.e. how many times do they occur in each document, in this case, each comment.

3 . Finally, we are ready to instantiate an LSA/LSI model. What does this model do ? It basically transforms our document-word_count matrix into a multiplication of
- document-topic,
- topic-topic, and
- topic-word_count
matrices, which essentially is and SVD operation.
This gives us the k most important ‘topics’ across the documents (comments in our case)

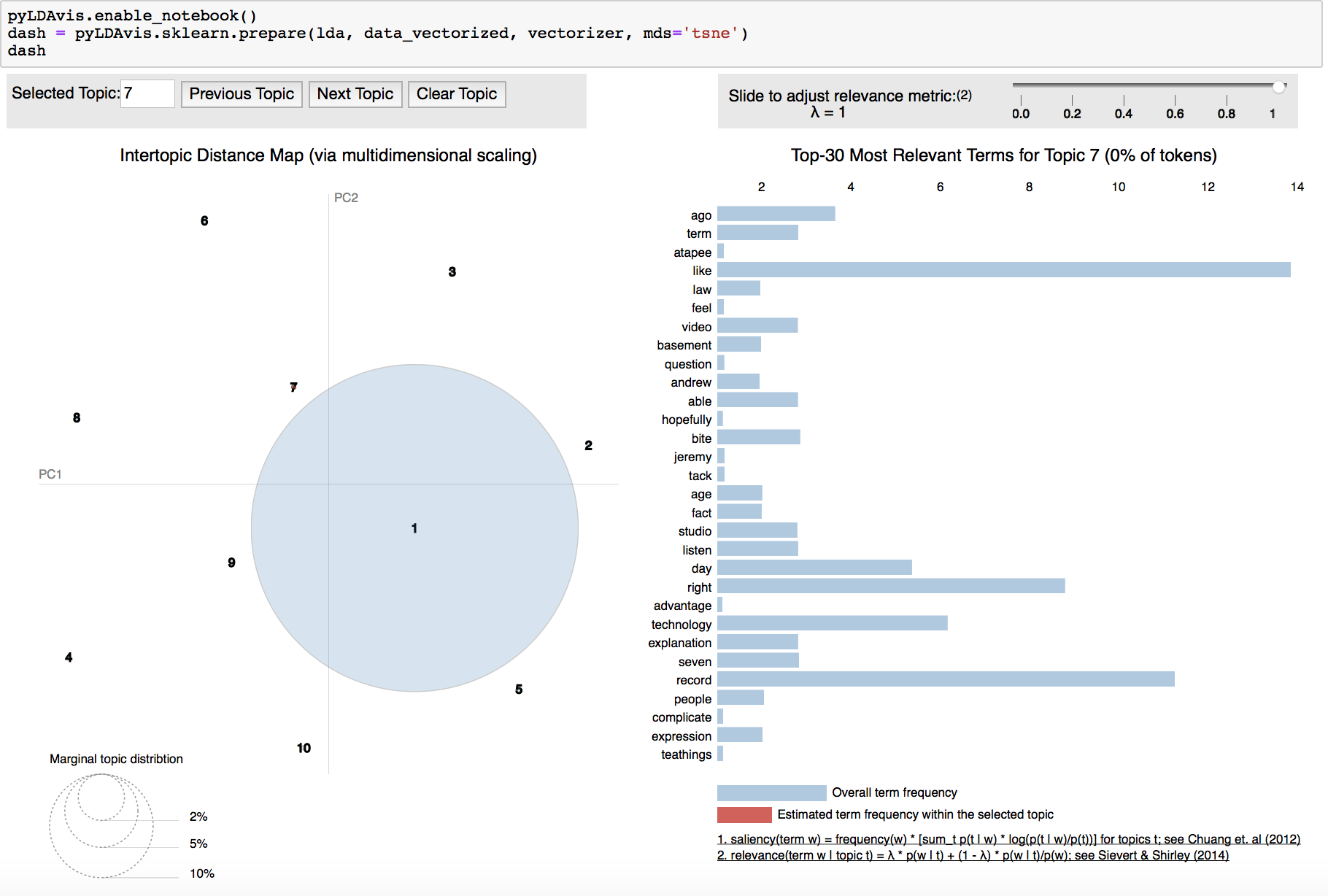
4 . Once the model is trained, we can now look at what topics are generated :

5 . We also explore slightly more advanced topic modelling approaches like the LDA. Will write more on that and other advanced deep learning based approaches in the next blogs though.
Sentiment Analysis
As a first step, instead of training a sentiment model from scratch (which we will be doing next), I researched the existing libraries, and nltk.vader (library and paper) stood out as a reasonable baseline. How does this work ? This is an excellent short read for the answer but TL;DR –> first each word is given a sentiment value (between -4 to 4) based on an sentiment intensity map a.k.a the VADER sentiment lexicon. Then these numerical values are aggregated across a sentence with required normalization to score each sentence between -1 and 1. Vader additionally uses these heuristics to augment these scores’ intensity:
- punctuation - “I like it.” vs “I like it!!!”
- capitalization - “amazing performance.” vs “AMAZING performance.”
- degree modifiers - “effing cute” vs “sort of cute”
- shift in polarity due to “but” - self-explanatory
(all sentiment-bearing words before the “but” have their valence reduced to 50% of their values, while those after the “but” increase to 150% of their values.) - examining the tri-gram before a sentiment-laden lexical feature to catch polarity negation (From the paper - By examining the tri-gram preceding a sentiment-laden lexical feature, we catch nearly 90% of cases where negation flips the polarity of the text. A negated sentence would be “The food here isn’t really all that great”.)
Results
First, we put these three tasks (word count, topic model, sentiments) as apis using Flask + Python (Code here). To make this really usable, we created a chrome extension. Once you are on a youtube video page, you can click this extension, and it should hopefully show results from all these 3 apis as can be seen in these example screenshots:
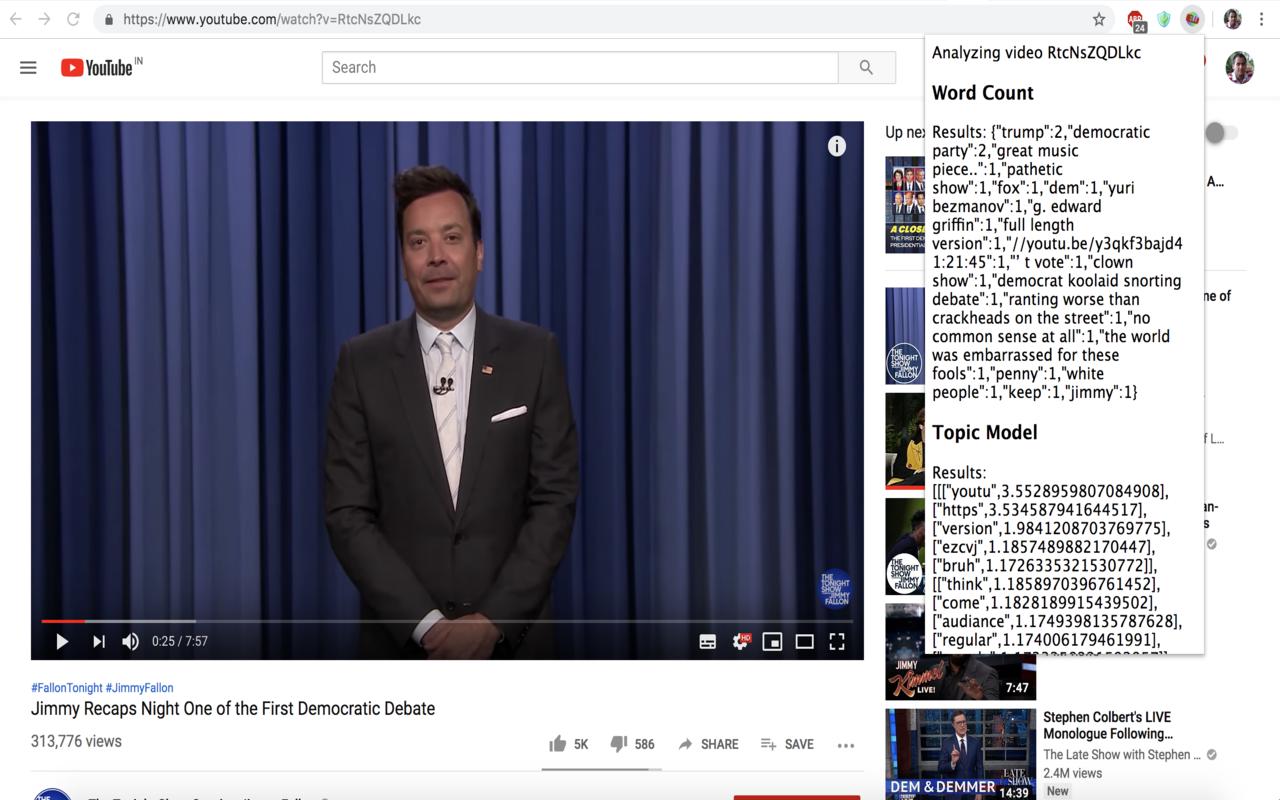
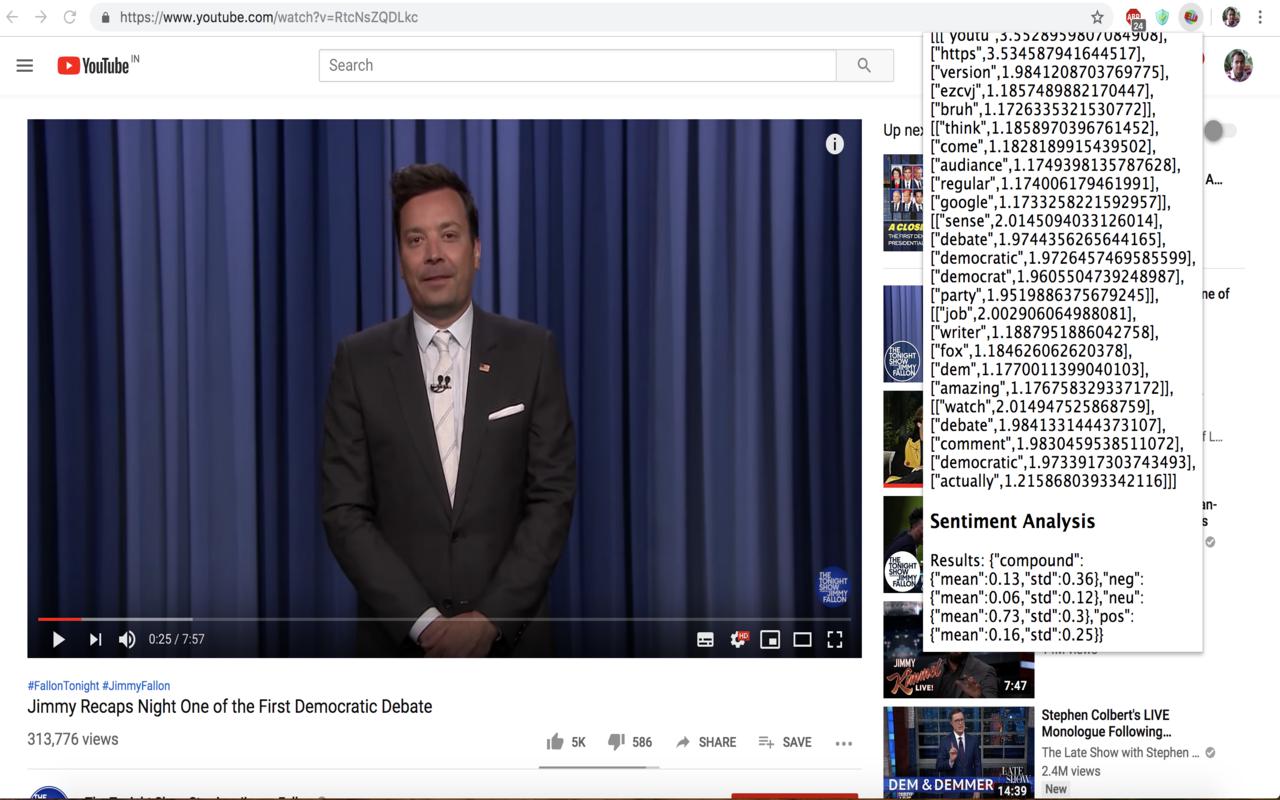
Here is the link to the chrome extension repo again. Clone the repo, upload the folder to chrome://extensions and should be good to go !
Acknowledgements
Big thanks to Akshay Kumar for discussing the initial ideas around this project. Special thanks to Neeraj Lajpal for his help with creating the chrome extension. Link to his original repo that we used for reference.
Next Steps
- More advanced models on topic modelling as well as sentiment analysis to replace with the current ones.
- Better UI for the chrome extension that shows the high level stats more intuitively and is user-friendly.
- Expand the product to more streaming services beyond Youtube, that facilitate comments on their platforms.
Thank you for reading this post. Hope it was helpful !