Self Rewarding Lang. Models [Paper Summary]
1) Why is this paper interesting? It presents a self-improving LLM that outperforms various RLHF-trained LLMs, and opens an area of research where LLMs can be improved both in their ability to follow instructions and their ability to reward their own responses, resulting in lower dependency on explicit human labels/feedback, and better performance.
2) How did they technically accomplish this? They used a pre-trained LLM to first train on minimal human labels (instruction-following), and then iteratively on its own labels (rewards) generated via LLM-as-a-Judge prompting.
LLMs trained with classic RLHF are limited
Most state-of-the-art conversational or instruction-following LLMs of today are trained on human labels - be it full text responses per input prompts (Supervised Fine-Tuning or SFT), or ranked responses for a given prompt (Reinforcement Learning using Human Feedback or RLHF). The instruct-LLM training is done in two stages:
- SFT, where a pre-trained LLM is fine-tuned on labelled
<prompt, response>pairs, and - RLHF. In RLHF, a reward model is trained (in isolation) using human-ranked responses per each prompt over a set of prompts.
Using reinforcement learning, the SFT-ed LLM is fine-tuned on rewards generated by the reward model on responses generated by the SFT-ed LLM (for given input prompts).
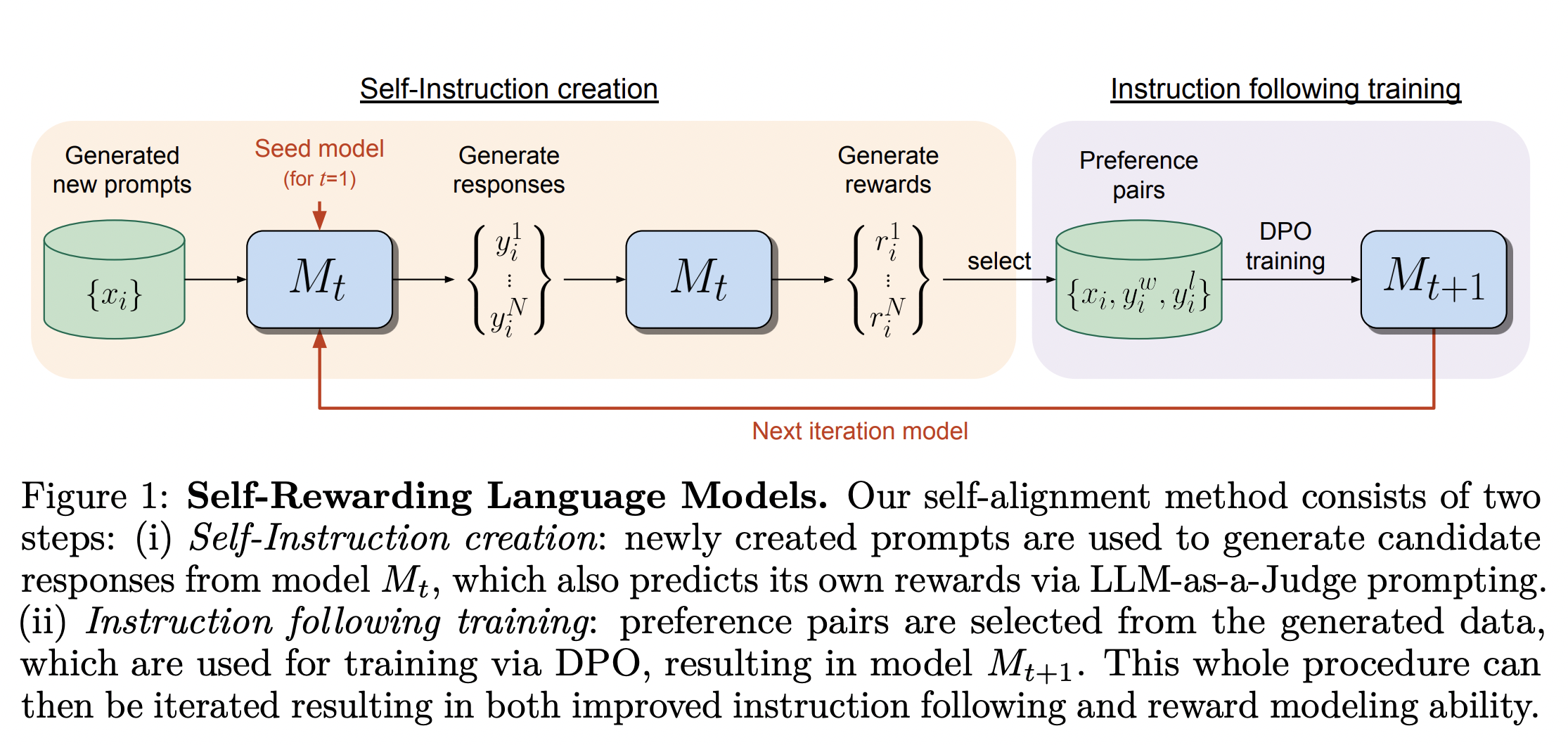
This process has two inherent limitations.
- First, the performance of the resulting LLM is upper-bounded by the human performance on such (chat or instruct) tasks.
- Second, the reward model that powers RLHF is trained only once, in isolation, and doesn’t improve with LLM training iterations.
This paper overcomes these limitations by presenting a self-learning mechanism, wherein, instead of relying on a fixed set of human labels, they use the LLM to generate its own labels and then train the LLM on those generated labels. In doing so, they achieve better performance on the task of instruction-following than many state-of-the-art LLMs that are trained on much larger volumes of human data.
How to train self-rewarding language models?
The training process is iterative. They use the pre-trained Llama 2 70B as the base model (they call it M0).
Using manual labels to fine-tune base LLM
At step 0, a small amount of human-labelled data is used for initial guidance (towards instruction-following). They first fine-tune the base model (M0) on 3200 human-authored instruction-following examples (<prompt, response> pairs) from the Open Assistant dataset (they call it the IFT - Instruction Fine-Tuning dataset), resulting in the SFT-baseline model. Next, they use 2306 ranking examples from the Open Assistant dataset containing human-ranked responses for various prompts (they call it the EFT - Evaluation Fine-Tuning dataset).
This ranking dataset is converted into the following format : <LLM-as-aJudge-prompt, output_score(from 1 to 5)>. The input prompts from the ranking dataset are converted to LLM-as-a-Judge prompts as per the template shown in figure 2. These prompts are then run through the SFT baseline model to produce an output score between 1 and 5. The authors retain those examples from the dataset where the output from LLM aligns/agrees with the human rankings. Of the 2306, they use 1175 formatted ranking examples to train (fine-tune) the SFT baseline model, and 531 examples for validation/evaluation. They call this fine-tuned model M1.
Training LLMs using LLMs
M1 onwards, they stop using any human-labelled data. They do the following to generate training data instead. They use Llama 2-Chat 70B model to generate more prompts using few-shots prompting (8-shots) on the original 3200 prompts available from the IFT dataset. They run these generated prompts through the M1 model to generate 4 different responses using top-p sampling with temperature T = 0.7 and p = 0.9. Each of these 4 candidate responses along with the input prompt are formatted as 4 LLM-as-a-Judge prompts as per figure 2. The 4 formatted prompts are then fed to the M1 model to produce scores between 1 and 5. Each prompt is ran 3 times, producing 3 scores and an average score is calculated as final.

Of the 4 candidate scores, the highest and lowest scored responses (referred to as preference pairs) are taken, and combined with the original input prompt into the following format: <prompt, (winning_response, losing_response)>. This formatted dataset is used to fine-tune the M1 model using Direct Preference Optimization (DPO - a kind of RLHF algorithm that uses preference pairs as opposed to indivudal response rewards). The resulting model is called M2. (Instead of DPO-ing over winning and losing responses, they also tried to simply SFT the M1 model over the <prompt, winning_response> pairs, but the results were worse than M1 itself.)
Performance of Self-Rewarding LMs versus LLMs
A total of 3964 data samples (prompt, with winning and losing responses) are used to train M2 from M1. This type of data is referred to as AI Feedback Training data or AIFT, where AIFT(M1) = 3964. This process is repeated to train M3 using M2 with AIFT(M2) = 6942. The authors decided to stop at M3. M3 outperforms M2 outperforms M1 outperforms SFT Baseline in terms of win-rates over a set of diverse 256 test prompts (derived from AlpacaEval evaluation prompt) in comparison to GPT-4, as shown in figure 3.
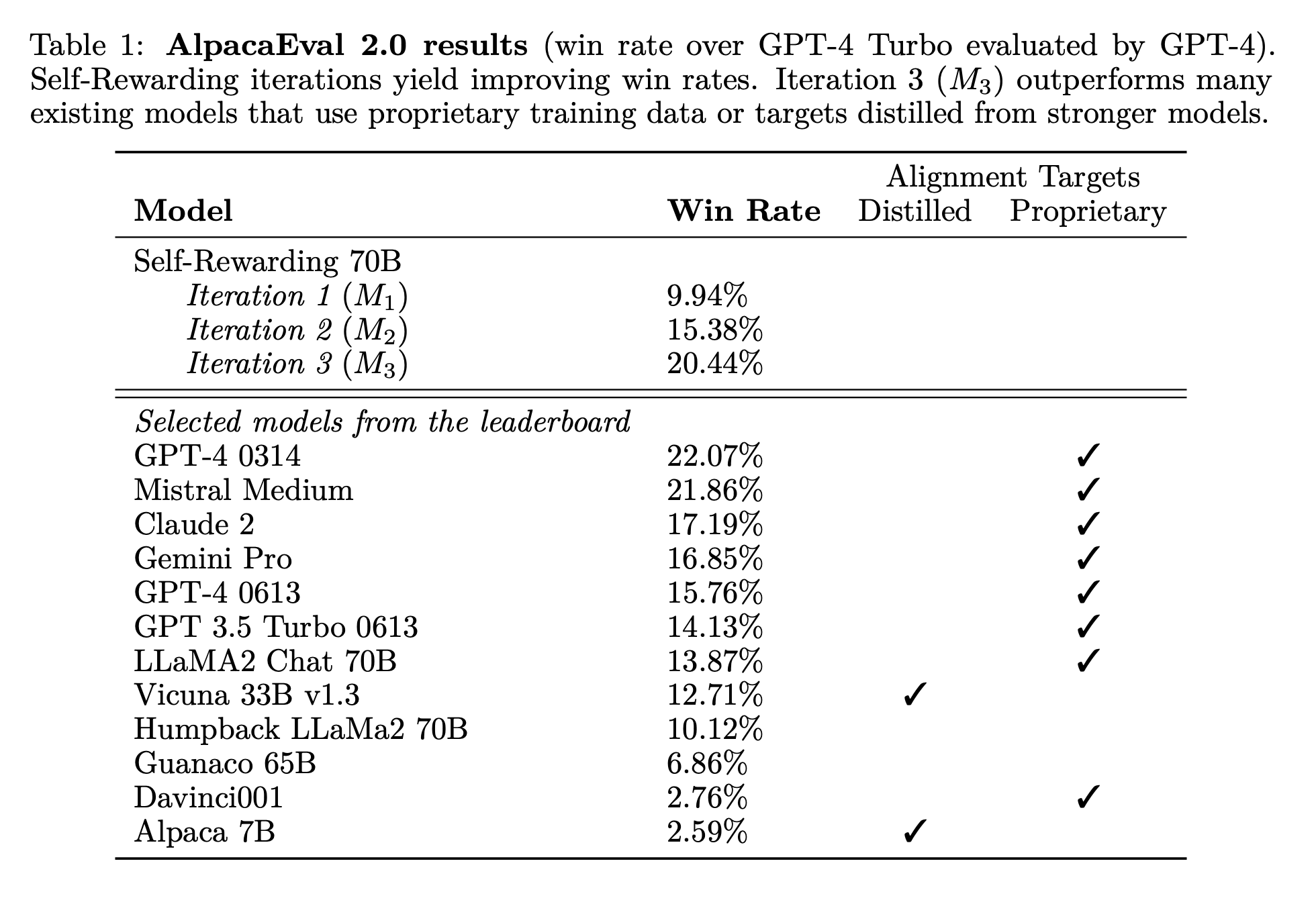
More importantly, M3 outperforms various state-of-the-art LLMs such as Claude 2, Gemini Pro, and GPT4 0613 (a variant) in terms of win-rates against GPT-4 as reported on the AlpacaEval 2.0 leaderboard. Even M2 outperforms Llama 2-Chat 70B on this leaderboard. This indicates a significant potential in self-improving LLMs that can outperform fellow LLMs without requiring much human feedback. It is worth exploring how far can we go this route (M4, M5, etc.) in reaching superhuman performance. It is also important to consider AI safety in this decreasingly manually-intervened paradigm of LLM training.
Thank you for reading this post. Hope it was insightful.