My First Python Package
Text detection in images is a well known computer vision problem and has been addressed by many approaches. One of them is Character Region Awareness for Text Detection (CRAFT). While working on a task that involved text detection, I stumbled upon the CRAFT paper and its working implementation. The implementation, while works wonderfully, is quite raw i.e. one needs to clone it, manually download models, set environment variables and run scripts. This post is about putting this implementation together as a PyPI package i.e. making it pip-installable.
CRAFT
Its a novel character level text detection. Here are a few highlights of this paper/approach:
- it uses character region scores (intra character) and affinity scores (inter character) to compute character level heatmaps and thereby computing word level bounding boxes using connected components approach. Figure below shows the model architecture which involves conv as well as deconv layers and two outputs - region and affinity scores:
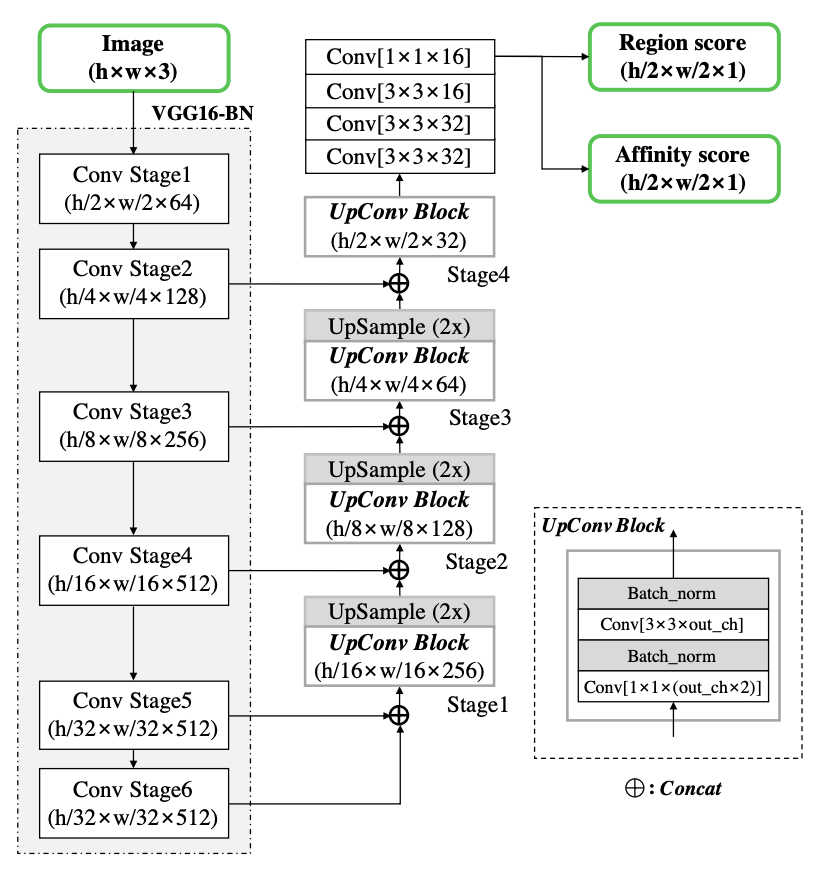
- affinity bounding boxes are deterministically computed from character bounding boxes without the need for any any additional labelling as follows:
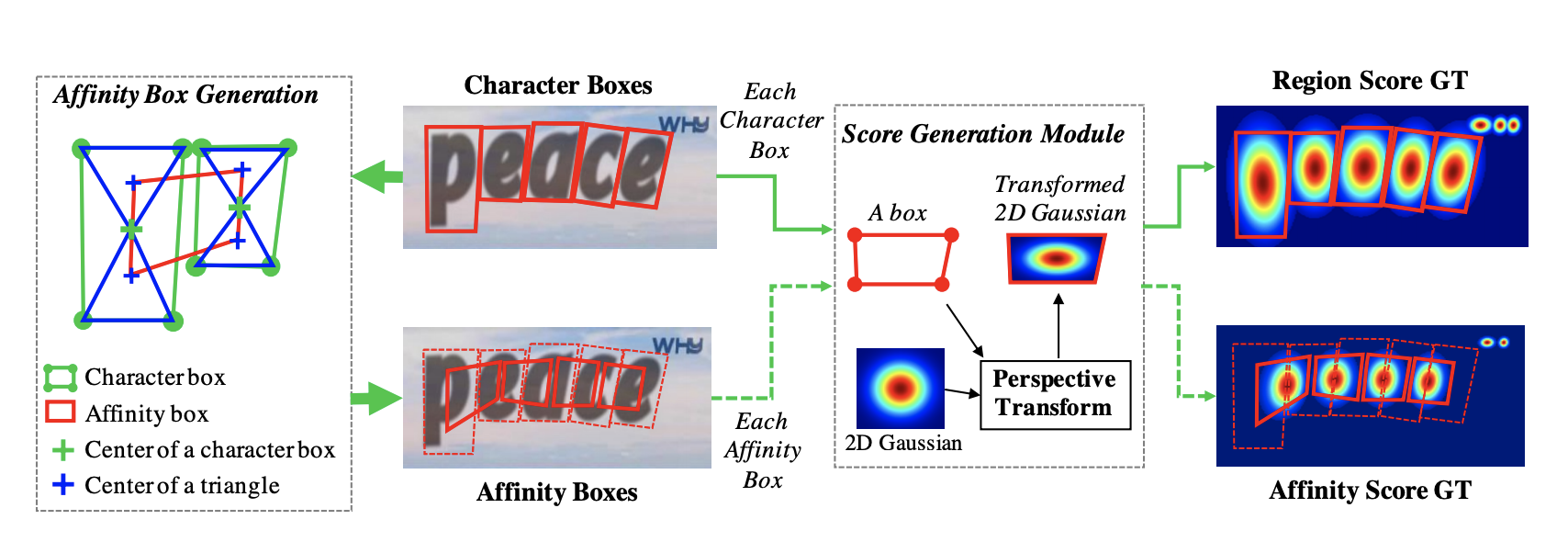
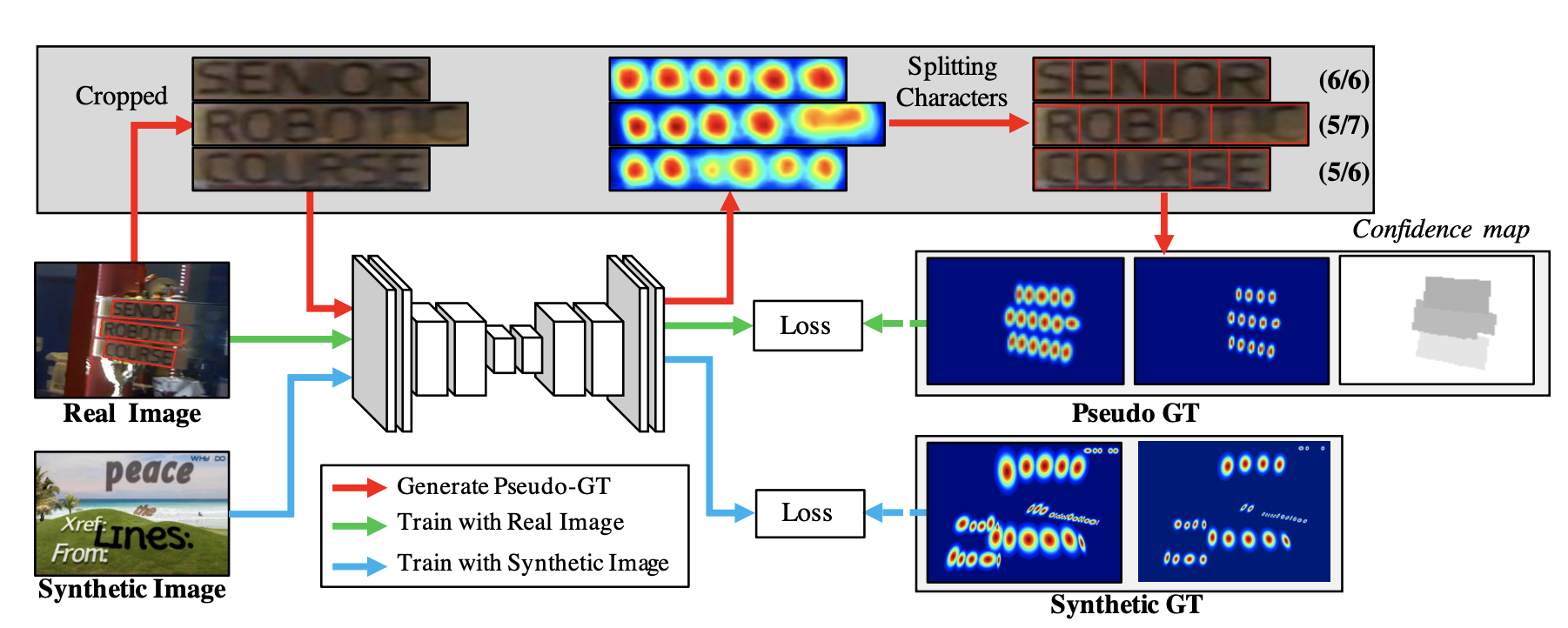
- it uses weak supervision in that the training is performed hardly on synthetic images with well-labelled character level bounding box coordinates and softly with real images with just word level bounding box coordinates, as shown in the figure below:
-
it uses confidence maps during weak supervised learning to de-prioritize instances where the number of characters detected by the interim trained model doesn’t match the word length in ground truth.
-
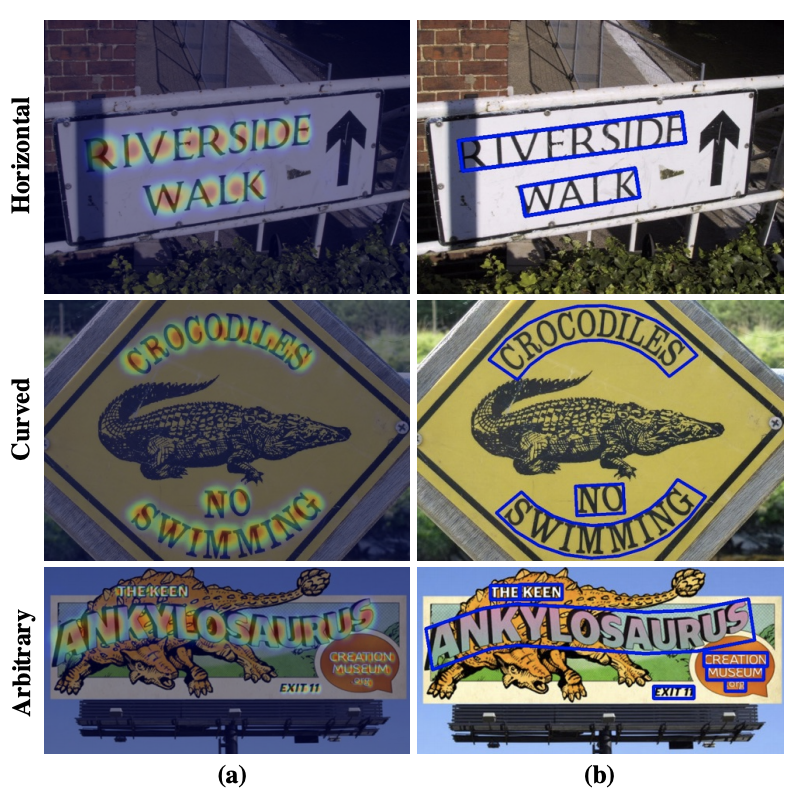
finally, because its character level, it can work well with all kinds of texts - rotated, rounded, curved, etc. as demonstrated in the figure below:
Existing implementation
Through this amazing website – papers with code I discovered a functioning implementation of this paper. The code there basically is the inference code and the readme contains links to pretrained models. But you have to manually download the models, install requirements, edit the inference code to make it all run. Details are provided in the readme of the repo.
Packaging it all
In order to re-use this implementation straight out of the box across projects, the current way of implementation fell short, which is when I decided to put it together as a PyPI package. Concretely, this meant:
- having proper object oriented code with classes, methods as opposed to one script
- having a design that facilitates a simple import entry point
- tests, extremely important !
- a setup.py file that helps compile the package as per PyPI standards
- finally, creating dist files and uploading it to the PyPI server
The revamped version of the project now exists as my fork from the original implementation which can be found here
Outcome
We now have a python package called craft-text-detection running live ! Using this package is as easy as:
! pip install craft-text-detection
import craft
import cv2
img = cv2.imread('/path/to/image/file')
# run the detector
bboxes, polys, heatmap = craft.detect_text(img)
# view the image with bounding boxes
img_boxed = craft.show_bounding_boxes(img, bboxes)
cv2.imshow('fig', img_boxed)
# view detection heatmap
cv2.imshow('fig', heatmap)
The figure below demonstrates these few lines of code in action
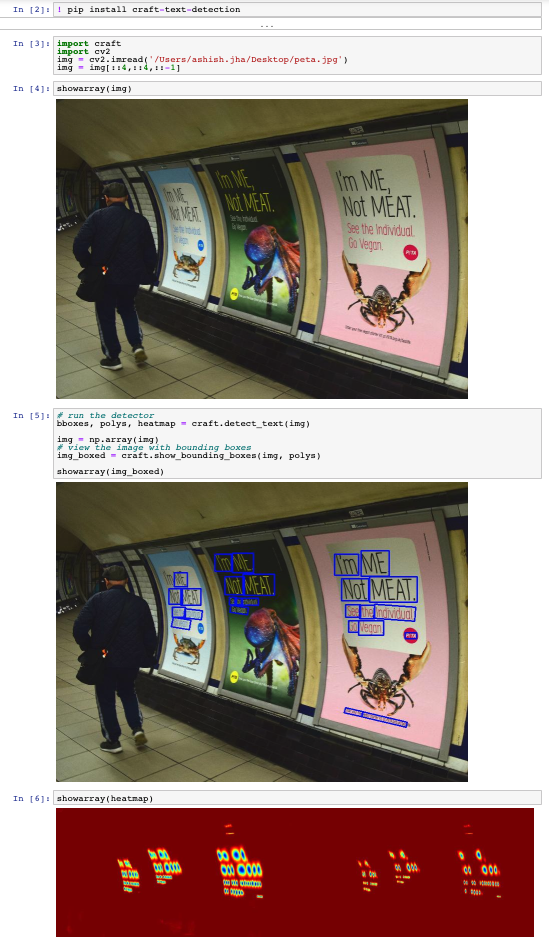
Quick notes on this demo :
- There are 2 heatmaps in this picture : (left) one for region scores and (right) one for affinity scores.
- I have just downsampled the image for faster inference and changed channels from cv2 BGR to RGB.
img = np.array(img)is an extra step needed for the reshape in the findpoly function to work properly downstream.
Usage and source code details can be found here
As an aside, I have made a PR to the authors of original implementation, hoping it gets merged :fingers_crossed:
Acknowledgements
Big thanks to Clova AI Research for both the interesting paper as well as a functional implementation of the same.
Next Steps
- Add functionality to choose pre-trained models while importing module (currently it downloads a default model).
- Add more methods / parameters-on-existing-methods to avail more control at user’s end on performing text detection.
- Better sanitization of the package (more tests, better design still).
Thank you for reading this post. Hope it was helpful !